# 建築圖面分類 × YOLO 影像辨識的實務實驗紀錄
在前三篇分別針對鋼構圖、結構圖、建築圖進行了YOLO圖紙分類實驗,但卻發現「明明都是按平面圖、立面圖、詳細圖等類型作標註分類」,為什麼卻出現了以下幾個結論?
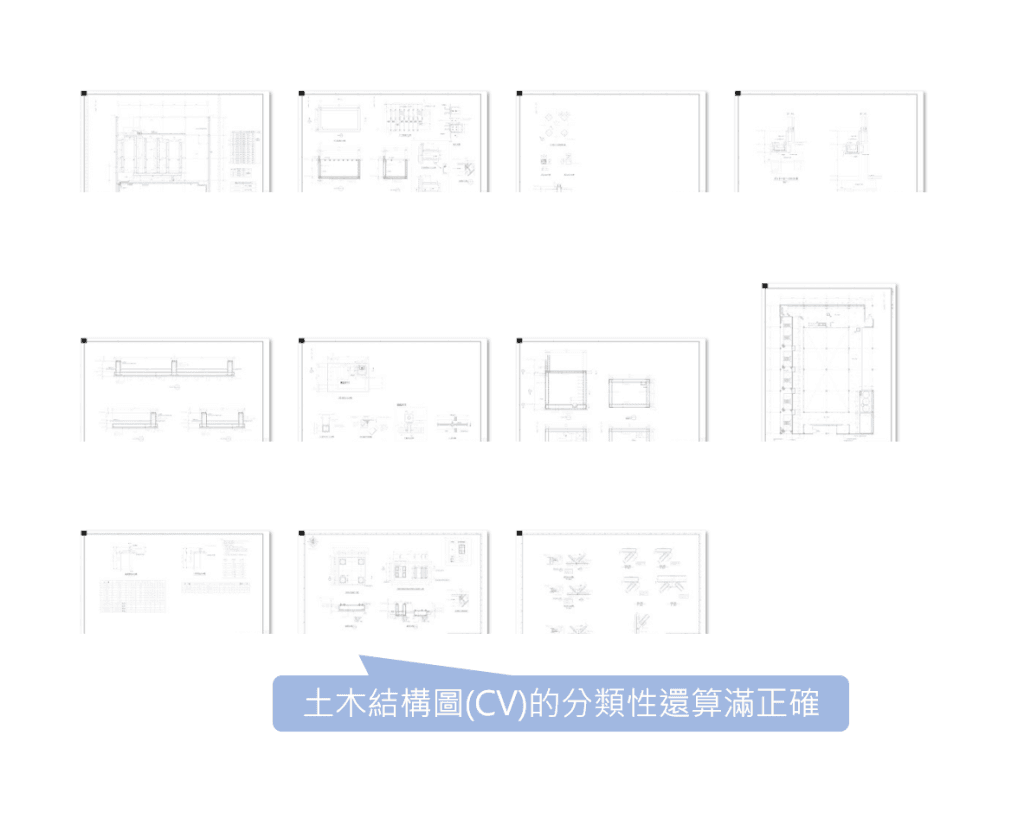
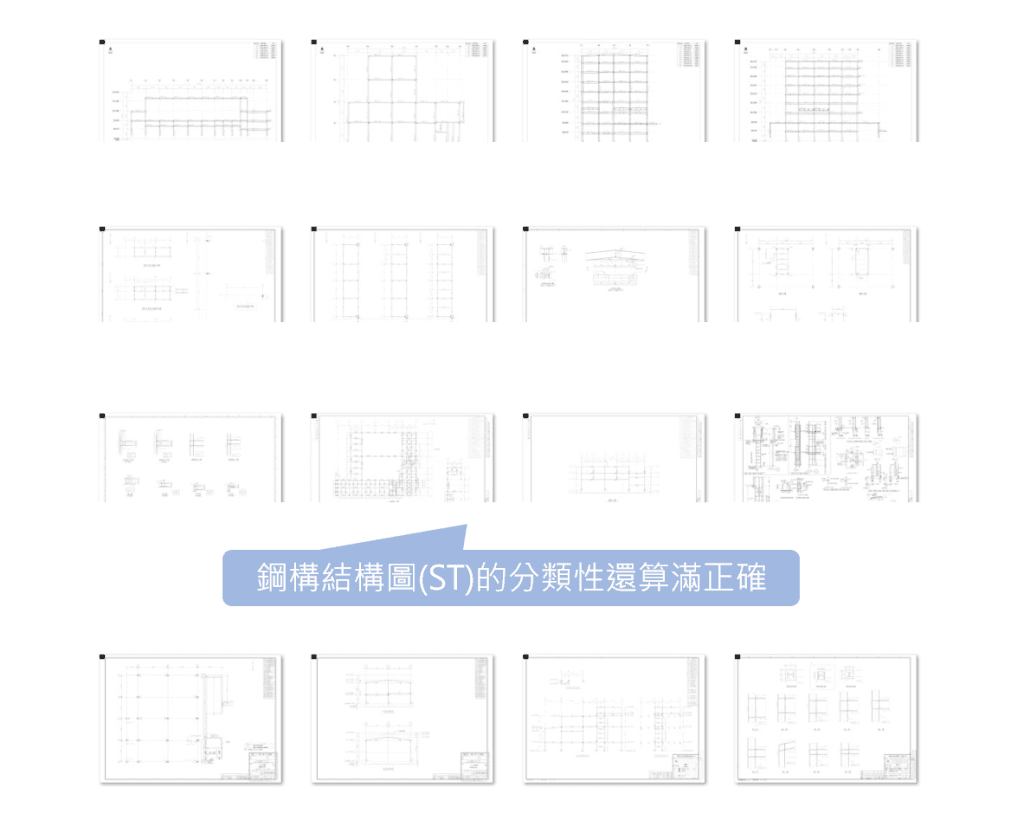
- 鋼構圖(ST)、結構圖(CV)可以正確的按平面圖、立面圖、詳細圖等被分類,惟資料集樣本數較小而限制了模型的成效
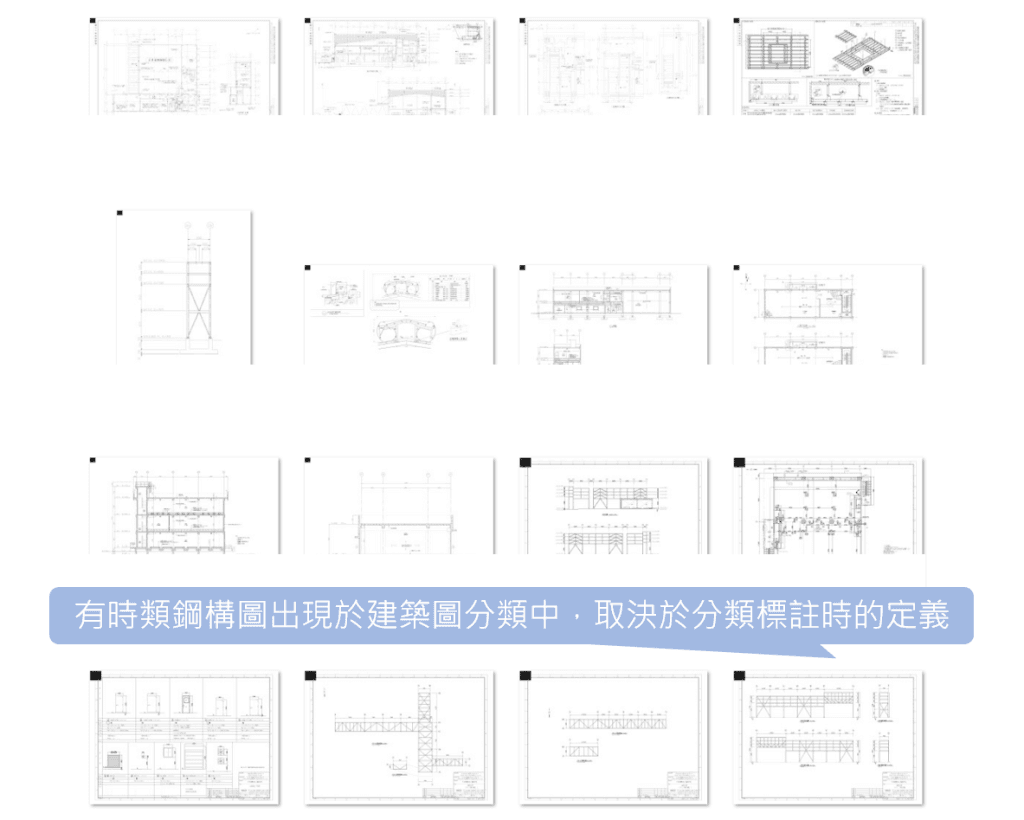
- 在圖紙內容較相似的建築圖(AR)當中,標註定義更甚於模型精度之前成為了限制
- 當圖面構圖或視覺特徵不足以判斷分類時,勢必需引入非影像資訊作為輔助
根據前面的實驗結果,圖紙的分類好像並不那樣穩定?所以,為了確認 YOLO 模型究竟適不適合拿來應用於建築圖紙的分類,本篇再以分類鋼構圖(ST)、結構圖(CV)、建築圖(AR)這三種類型的圖紙作為實驗。
實驗結果觀察
AR / CV / ST 比較像是功能性分類,而非視覺分類
在實務流程中,我們會直覺式的透過圖面的視覺特徵(外觀),很容易的區分出不同圖紙的類別,並且作圖紙管理與工作分工的依據(例如:這張內容畫的是柱配筋圖,因而判斷它是結構圖;這張畫的是建築物外觀,因而判斷它是建築圖….等)。但殊不知這一系列的流程判斷,其實做的比較像是功能性分類,而非視覺分類。
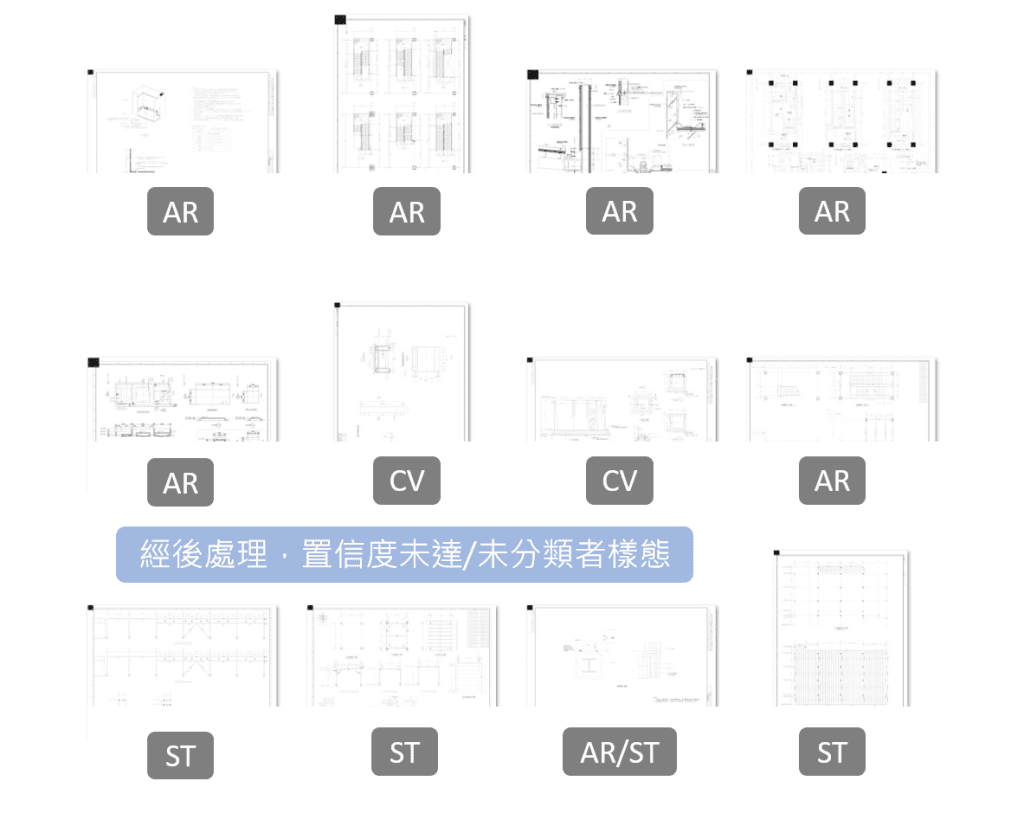
YOLO影像識別(物件偵測)模型能夠學習這圖面內容的視覺關聯,卻無法直接判斷其在實務流程中的角色定位。換句話說,YOLO 分類可以做的是「我看到哪些構件(物件)」,而不是直接能判斷「我覺得這張是什麼圖」。因此才會發現,即使模型訓練穩定,分類結果仍難以具備一致的語意意義。
系列實驗結論
物件偵測 vs 功能用途 本質性的不同
當分類依據來自流程語意而非視覺特徵時,要求影像模型提供穩定分類結果,本身即存在先天限制。就像起初以平面/立面/詳圖 的定義去作分類標註,其實是按著圖面內容的「畫法」、「視覺特徵」去區分:
- 鋼構圖(ST):內容核心聚焦在構件與尺寸的樣態,物件視覺樣式近似於用途
- 結構圖(CV):配筋、基礎、符號有規律的視覺特徵,但偶有說明圖混入,分類穩定性開始受影響
- 建築圖(AR):由於圖面本身混雜多種用途,所以模型優先學到的是「版面風格」,以致限制了對功能用途差異的判斷
而本篇 ST/CV/AR 分類的本質其實是—「這張圖在流程中要負責什麼」
看出差別了嗎?YOLO 分類模型所做的是:「這張圖長得像不像某一類平均圖」;但 AR / CV / ST 問的是:「這張圖現在在這個案子裡要幹嘛」,也就是說物件偵測和功能用途的分類,本質上就是兩個完全不同的問題。
結語
本次實驗顯示,YOLO 影像分類在建築圖面中仍具可行性,但當類別的定義不是純視覺可區分時,模型仍可學到「趨勢」,影像與物件特徵可以支撐作為分類的依據;但當用途取決於專案階段與溝通情境時,僅依賴影像與物件偵測,將無法穩定對應圖紙的實際功能,即模型精度自然會受限。
延伸閱讀
若你也是非本科背景,想系統性了解 YOLO 從 0 建立環境、準備資料集到實際應用的流程,可以參考我整理的基礎流程教學課程: (本課程為流程教學導向,並非本系列實驗文章之方法或結果重現。)
👉 課程連結(PressPlay Acadmey):【線上課程】零基礎一次搞懂! 用YOLO打造自己的 AI 辨識工具